Computer Vision(CV)
参考Stanford CS231课程,我的计算机视觉基础笔记
有Machine Learning和Deep Learning基础食用更佳
Classification
分类任务在机器学习中很常见,对于视觉任务,即是把图像(picture)归为标签(label),例如:{cat,dog,car},我们需要找到某种从图像到标签的逻辑关系,并利用这种逻辑关系进行预测。
def train(images, labels):
# Machine learning
return model;
def precict(model, test_images):
# Use model to predict labels
return test_labels计算机能读懂的是数字,而不是图像本身。一张图像本质上是像素点的排列,每个像素点有不同的取值,比如在RGB图像中,红/绿/蓝分别分别可以取值[0,255],一张800*600大小的图像就有800*600*3个参数,我们研究的本质还是如何对数据进行处理。
但是,分类任务还会遇到许多问题:semantic gap(语义鸿沟)/viewpoint variation(视角多样)/illumination(光照)/deformation(变形)/occlusion(遮挡)/background clutter(背景)/intraclass variation(类内变异)/…
一般来说,会依据具体的任务设计预处理/模块/网络/正则化,通过训练和调参来缓解这些问题。分类任务作为最基本的任务能衍生许多方法,成为了我们研究视觉任务的抓手。
K-Nearest Neighbor(KNN)
俗话说“物以类聚,人以群分”,如果有一个很大的样本库(如CIFAR-10),里面有各种类型的图像,我们可以通过比较需要分类的图像它们之间的相似度来选出最有可能的类别。
最直接的我们可以对图像的每个像素点进行直接比较$d_1\\$。当然,按照KNN的想法,我们有欧式距离$d_2\\$衡量不同图像的差异,并且设置超参数(hypermarameters),对需要分类的图像距离最近的k个类型进行投票,票数最高的就是预测的类别,超参数k往往需要通过实验获得。实验设置上我们往往要分train(训练集)/validation(评估集)/test(测试集),评估集的作用主要是惩罚训练集的过拟合,而测试集检验了模型的泛化能力。
$$
d_1(I_1,I_2)=\sum_p|I_1^p-I_2^p| \\
d_2(I_1,I_2)=\sqrt{\sum_p(I_1^p-I_2^p)}
$$
但是,KNN会有两个致命的问题:一个是随着参数量上升导致的维度爆炸,另一个是过于关注像素点而忽略图像某个区域的特征,无法表示视觉感知的差异。
Linear-Classification
另一种方式是,我们为图像和标签建立一个函数关系,最简单的就是线性函数。
$$
f(x,w)=wx+b \\
$$
例如,我们要分10种类型,通过线性分类模型,我们最后会得到一个10*1的矩阵,每个元素代表“该分类的评分”,我们把32*32*3的RGB图像展平成一个3072*1的向量,根据矩阵运算法则,我们需要构建一个10*3072的$w\\$矩阵,和一个10*1的$b\\$向量,当我们输入图像的向量后,输出10个评分,值最大的就是预测的类别。而$w\\$和$b\\$参数的矩阵需要通过对神经网络进行训练获得。然而,线性关系还是很难捕捉图像和标签之间的复杂关系,引入非线性关系是必要的。
Convolutionnal Nueral Networks
为了捕捉图像和标签之间的非线性关系,我们引入了卷积神经网络。卷积神经网络的结构与常规的神经网络并没有区别,关键在于“卷积层”可以提取“图像特征”,也因此被广泛用于分类/识别/理解等视觉任务。
Convolution
重复上面的例子,假设现在有一个全连接层,输入是3072*1的图像矩阵,通过10*3072个权重的神经元,经过activation输出了1*10的标签矩阵。但是直接展平成一维矩阵会丢失掉区域的结构信息,我们能不能保持矩阵原先的形状,同时又能赋予其权重呢?
因此,我们引入了卷积核(filter)的概念。在这个例子中我们设定大小为5*5*3,赋予其75个权重,在卷积核和图像块之间进行点积运算,即将卷积核的权重和图像的像素值相乘加上偏置值($w^Tx+b\\$),得到一个数值。注意,在点积的实际操作中,卷积核会被展平成一维向量进行运算(参考numpy的原理)。
如果将卷积核逐步移动遍历整个32*32*3的图像,最后会得到28*28*1的activation maps,如果用不同的n个卷积核就会得到n层(不同的卷积核有不同的权重,可以理解为提取不同的特征)。
在卷积操作之后,我们往往会连接激活函数并输入新的卷积神经元,卷积核尺寸随新的输入改变,经历多次卷积,图像特征也会从低阶到复杂。本质上,每一次卷积操作就是一个神经元,有几个卷积核神经元就有多少层,通过降低平面尺寸提取了特征,但过多的特征提取也会导致信息的丢失。
卷积核遍历的时候我们可以设置一些参数,比如stride(步长),对于7*7图像,3*3卷积核,步长为1会得到5*5,而步长为2会得到3*3,但步长为3会无法对齐,为了解决这个问题,我们会引入padding,在边缘处补上人为设定数值的边框(一般为0/镜像值等),让卷积核移动时可以填满图像的边缘。在实际操作中,我们往往把卷积核的步长设为1。
map的边长计算公式总结如下: $$
x = (N-F+2*padding)/stride + 1 \\
$$ Pooling
如果网络中只有卷积层,我们的参数量依旧过大,不利于计算,我们需要引入平面的池化操作。
例如,Max Pooling即最大池化,设定一定尺寸的池化核,无交叉铺满图像块(如果大小超出边缘也无所谓,取最大即可,因此不需要padding),在每一个池化核内取最大值,代表“图像任意区域的受激程度”,既降低了数据的维度,又保留了每一个图像块的特征。一般我们会设置核大小为2*2,步长为2。
至此,我们得到了最基本的卷积神经网络循环结构Conv+ReLU+Pool,但具体的网络结构和超参数设置往往需要通过实验对比获得。
CNN
CNN本质上结合了深度学习和卷积神经网络的思想,通过增加深度和特征提取来处理视觉任务。
AlexNet
最早的CNN,根据实验得出了参数良好的卷积神经网络。CNN的原理我们已在上文提及,一般还会有Linear层控制数据的维度。

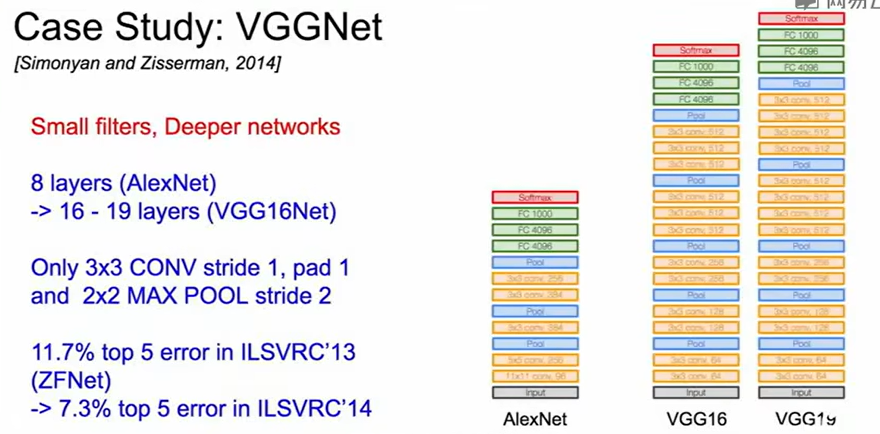
VGGNet
设计时对AlexNet改进,增加了网络深度的同时减少了参数量。核心即用多层小卷积核(3×3)堆叠,替代大卷积核(7×7、5×5),在保持感受野的同时大幅减少参数,还顺手多了非线性层数。

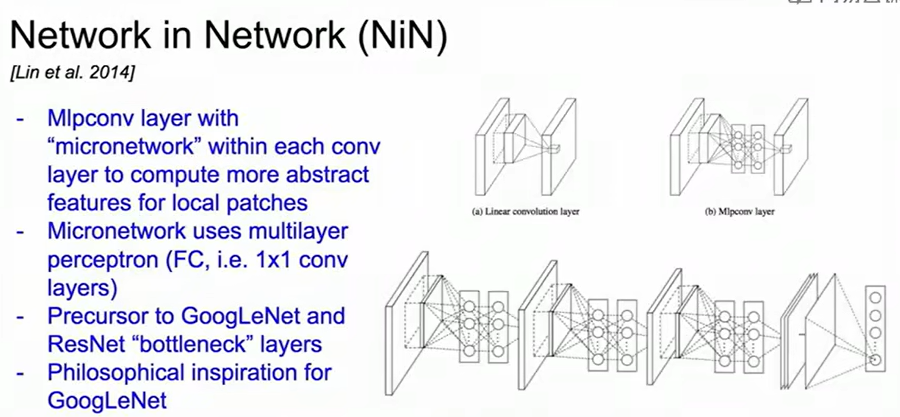
NiN
Network in NetWork,最早提出了bottleneck layers的概念,启发了后续网络的局部拓扑结构。简单讲,它在空间卷积后用1*1卷积压缩通道、再用1*1扩展映射回去,用来在保持特征信息的同时减少参数量和计算量,还增加了非线性。
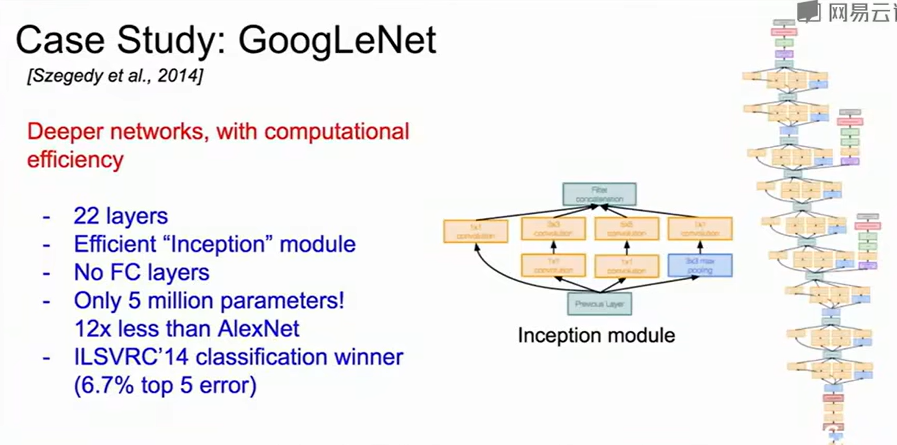
GoogLeNet
在增加深度的基础上加速了计算效率,提出了Inception module局部拓扑结构,用到了bottleneck layers的想法。
| 分支 | 结构 | 功能 |
|---|---|---|
| ① | 1 × 1 卷积 | 提取局部特征、线性变换通道 |
| ② | 1 × 1 → 3 × 3 卷积 | 先降维、再提取中尺度特征 |
| ③ | 1 × 1 → 5 × 5 卷积 | 先降维、再提取大尺度特征 |
| ④ | 3 × 3 MaxPooling → 1 × 1 卷积 | 聚合背景信息、补充稳定性 |
最后这4条分支输出在 通道维度上拼接成整体输出。
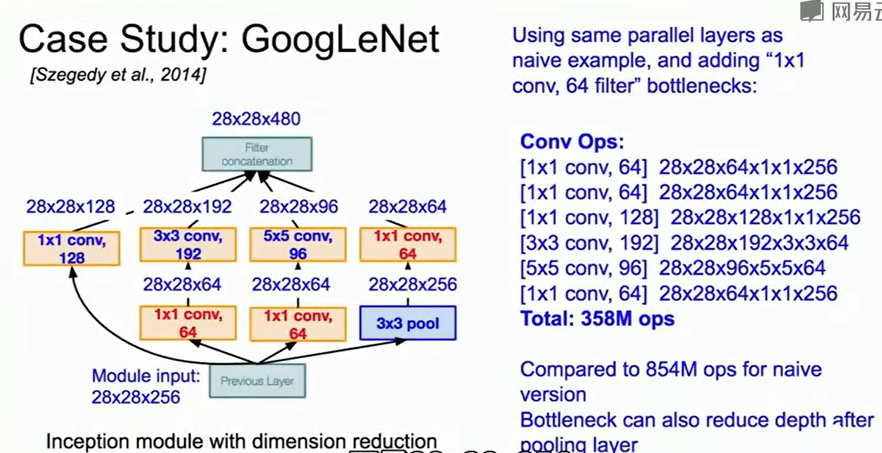
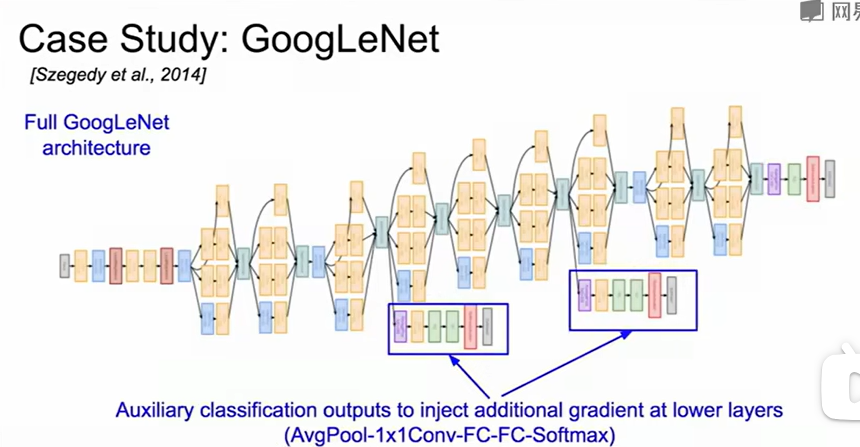
1.进行multiple convolution时,若尺寸不匹配会进行padding,方便最后对输出进行拼接。
2.网络太深了会出现梯度消失问题。为此在中间层插入了两个辅助分类头,帮助梯度反传。
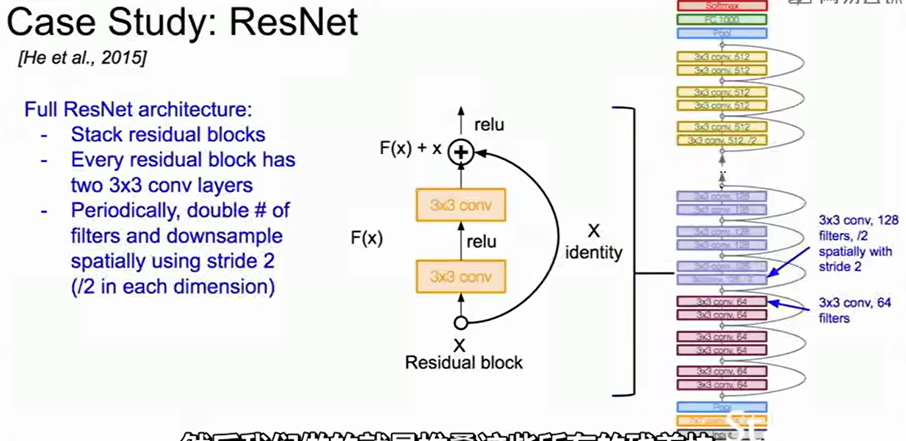
ResNet
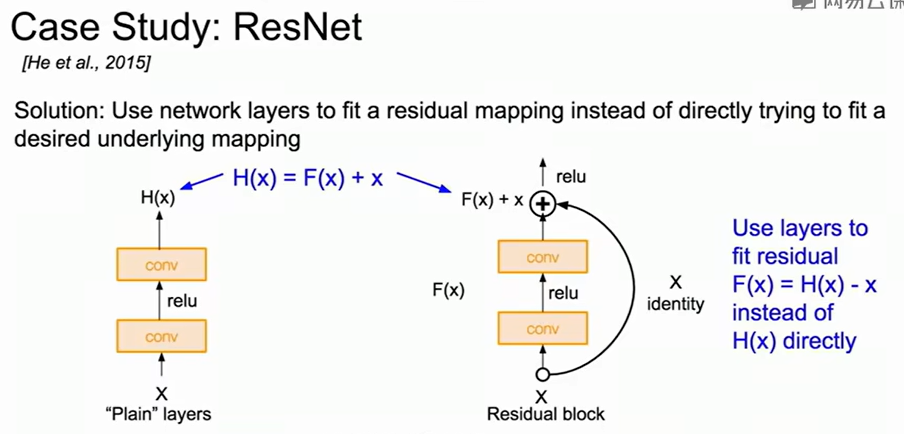
当网络更深,损失函数下降趋于平缓时更难优化,因此ResNet提出了残差的概念。假设我们想让若干层网络拟合目标函数$H(x)\\$,传统做法是让堆叠的卷积层直接学$H(x)\\$,而ResNet提出:不直接学$H(x)\\$,而是学「残差函数」$F(x)=H(x)−x\\$,于是输出为$H(x)=F(x)+x\\$。也就是说,这些卷积层不需要从零学到整个映射,只需学出相对于输入的微调。反向传播时,梯度可以直接沿着旁路流回前层,从而缓解梯度消失问题。
$$
\frac{\partial L}{\partial x} = \frac{\partial L}{\partial y}(1 +
\frac{\partial F}{\partial x})
$$ 因为恒等项1存在,即使 $\frac{\partial F}{\partial x}$
很小,梯度也不会完全消失。
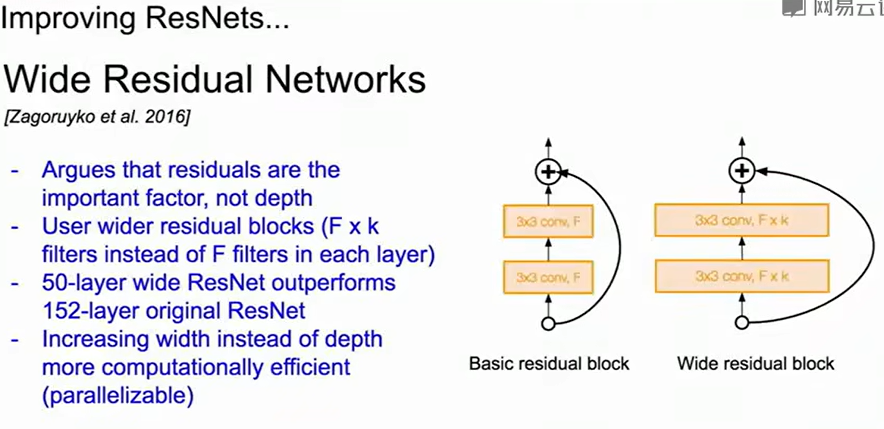
至于改进,我们会采用更宽的残差块,也就是增加卷积核的数量,或者像ResNeXt将残差块设置为多分支,原理是一样的。也可以用正则化的思路,引入随机深度,跳过一些残差块。
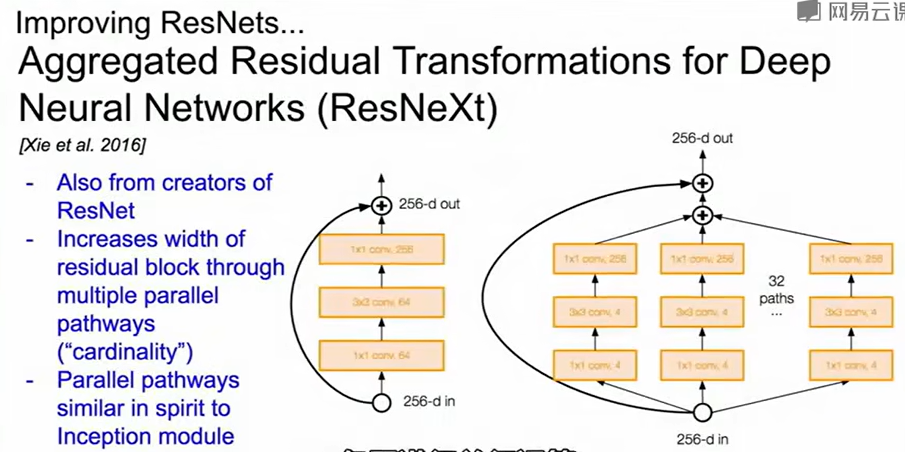

FractalNet
提出了分形结构$f_{c+1}(x)=f_c(f_c(x))+f_c(x)\\$,不用残差而自然形成多层路径长度。
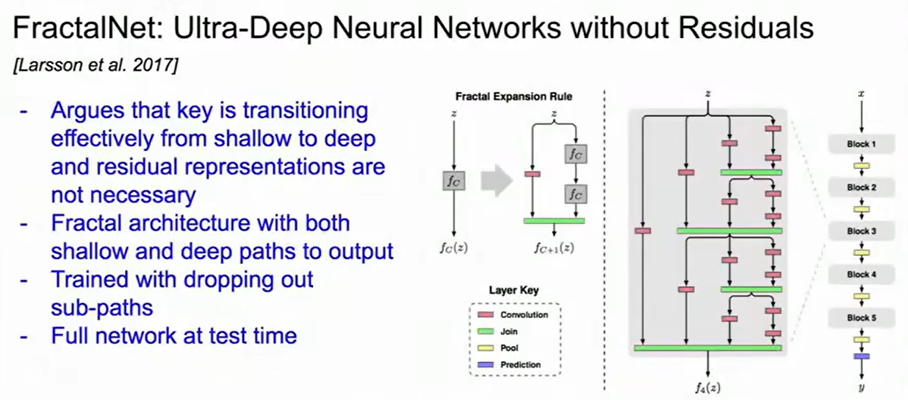
DenseNet
既然残差是相邻层的加法连接,那如果我们让所有层都互相连接,信息会不会更充分?从而提出了Dense Block,各层相互连接。$x_l=H_l([x_0,x_1,...,x_{l−1}])\\$,也就是说,第
$l\\$
层的输入是所有前面层特征的拼接。
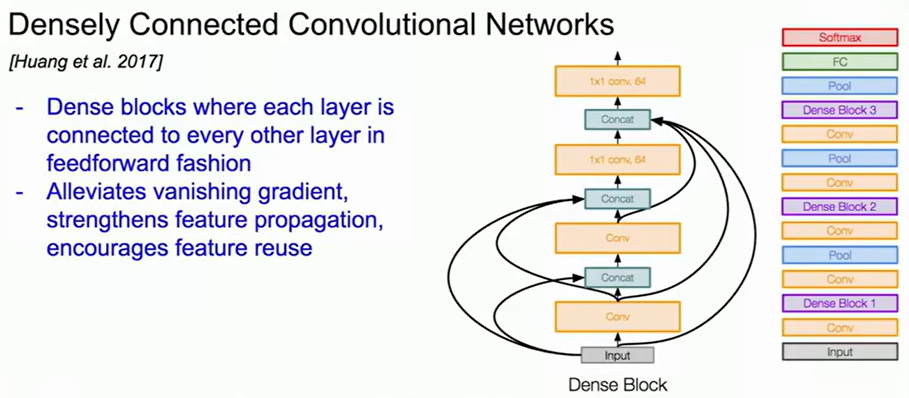
SqueezeNet
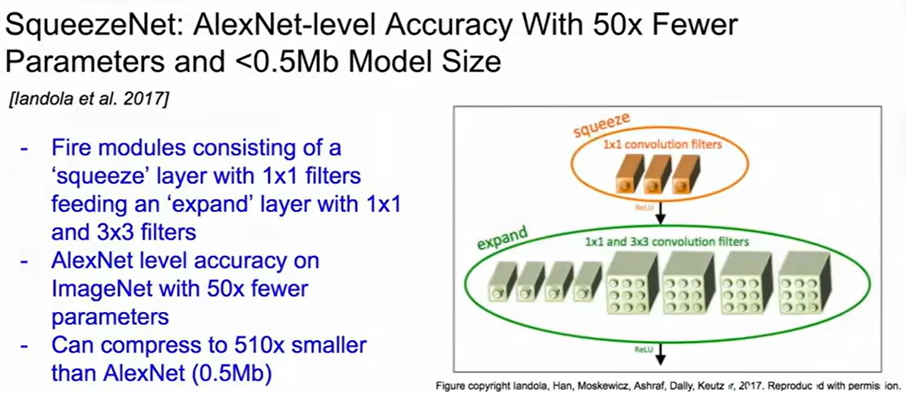
提出了fire module。Squeeze层用1×1卷积先把输入通道压缩(减少进入3×3的计算量,类似bottleneck),Expand层再用1×1和3×3卷积提取特征,1×1用于局部线性变换,3×3提取空间上下文。Concat输出把两种卷积的结果拼接起来(融合不同感受野)。
RNN
Principle
RNN即Recurrent Neural Network,循环神经网络。
RNN主要处理的任务可以分为以下几类:1.one to many,比如把图像理解为一个句子
2.many to one,比如对视频进行分类
3.many to many,例如翻译。RNN本身就是处理可变序列数据的神经网络。
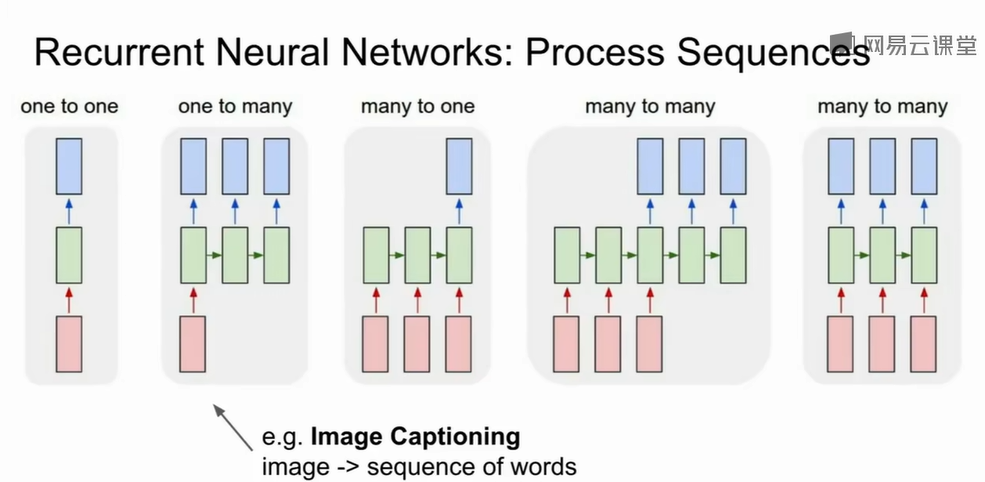
核心公式:$h_t =
f_W(h_{t-1},x_t)\\$。ht为当前时刻的隐藏状态(hidden state),可以理解为网络在时刻
$t\\$ 的“记忆”,$x_t\\$为当前时刻的输入(input),例如一个句子的第
$t\\$ 个词向量,$h_{t-1}\\$上一个时刻的隐藏状态,携带历史信息,$f_W(\cdot)\\$带有参数 $W\\$
的非线性变换函数,定义了如何将“过去的信息”和“当前输入”融合成新的状态。
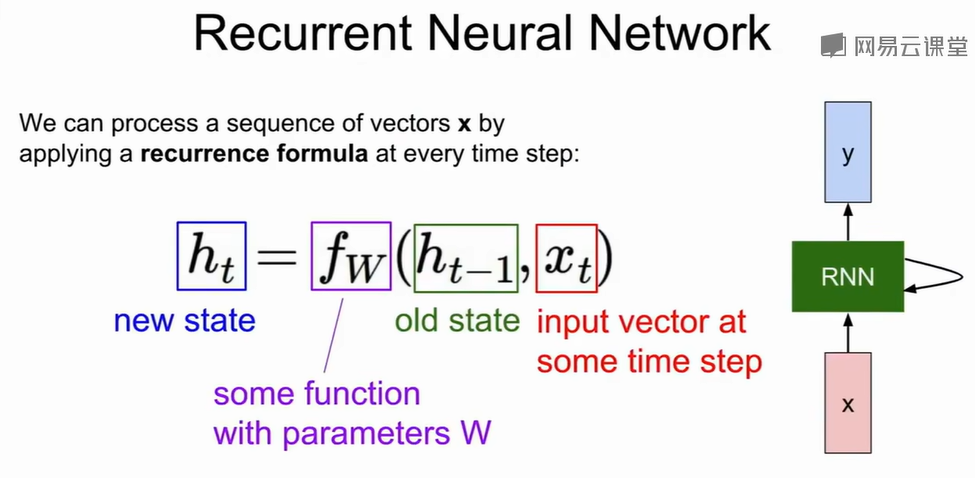
本质上是用相同的权重矩阵$W\\$,在每个时步通过旧状态和新输入更新出新状态。在one to many/many to one/many to many任务中的主要区别就是输入是否需要在每个时步中加入。
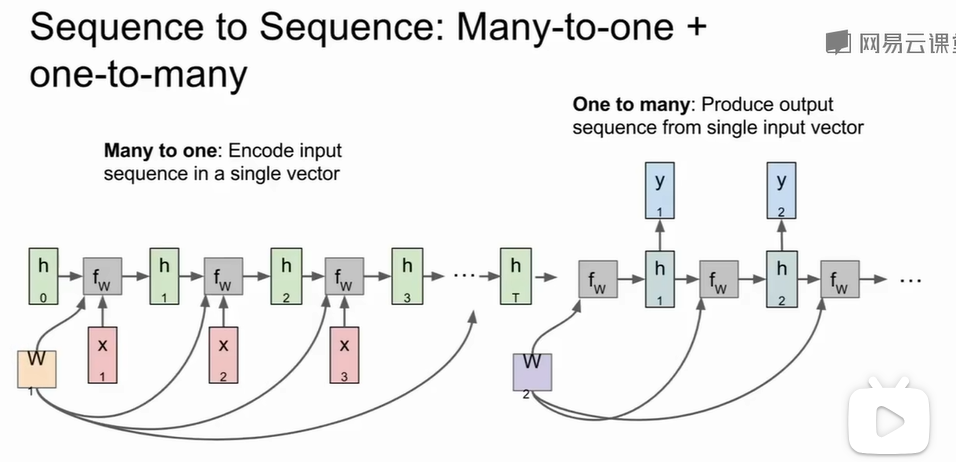
由于RNN具有可以捕捉序列的特性,最早被用于处理生成式模型的任务。每个时步内,隐藏层输出$h(t) =
tanh(W_{hh}h_{t-1}+W_{xh}x_{t})\\$,即基于输入向量和旧状态得到新输出,经过Softmax激活后概率最高的字母不仅会作为输出,也会作为下一个时步的新输入向量。
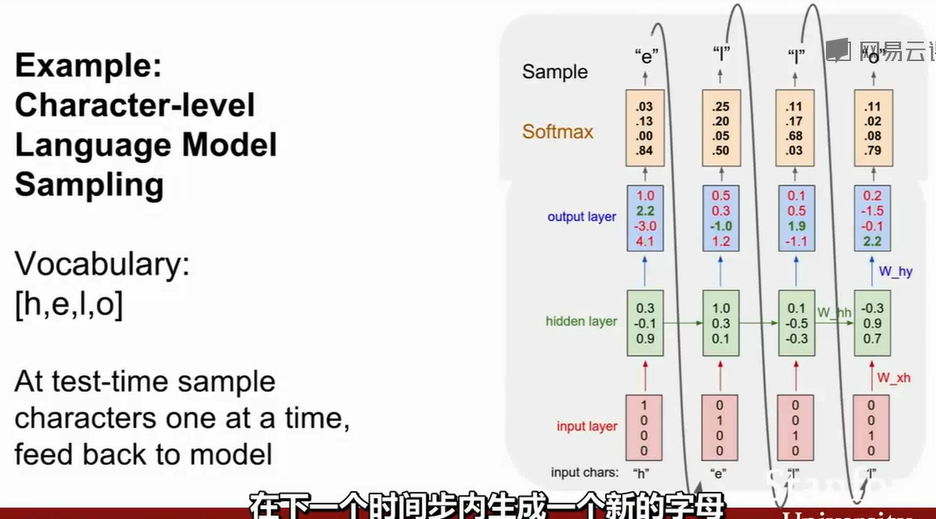
损失函数也在每个时步中叠加,而在计算损失函数时我们往往会选取片段时步的loss。
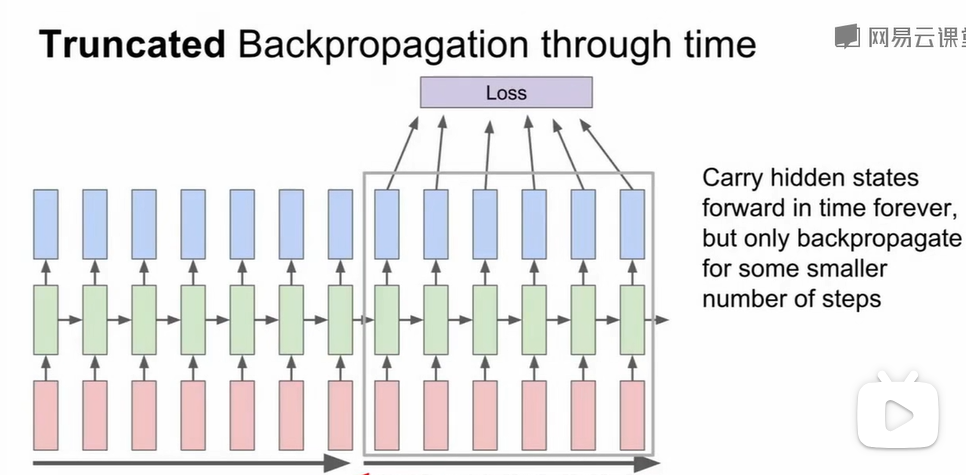
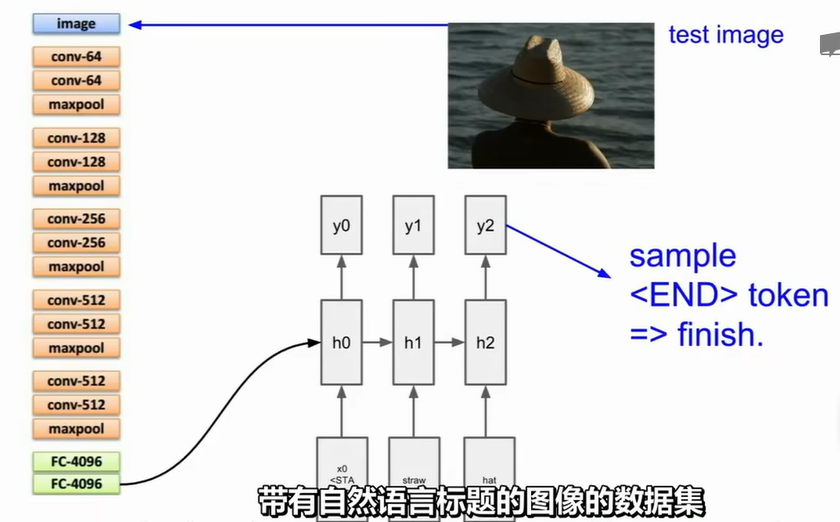
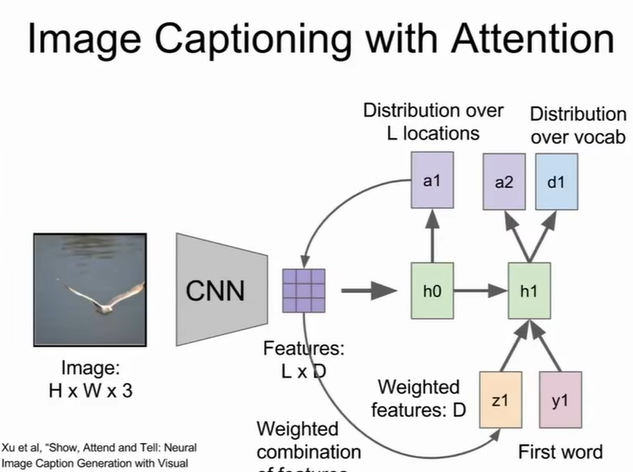
但训练RNN只是对后面出现的字母进行了预测,很难捕捉到和前面所有时步的关系,这也是后来为什么transformer捕捉到的attention横空出世改变了NLP领域。在图像理解任务中,我们也会用到RNN网络,比如下面one to many的例子。这个方法效果不佳,因为它没有捕捉到文本信息和对应图像块的联系。因此,我们引入了attention来捕捉这种联系,我们的输入修改为图像某一个区域的CNN结果,而每一个图像块有其对应的文本。
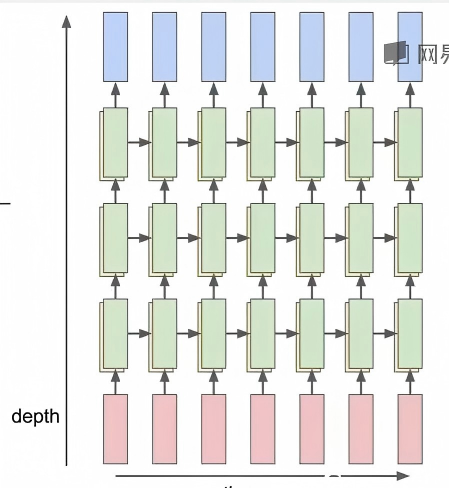
当然,RNN也是可以有多个隐藏层的,我们知道适当的增加网络深度可以提升性能。
LSTM
在计算反向传播时,从尾部传到头部会乘上非常多的相同矩阵权重因子,因子过大会出现梯度爆炸的问题,过小会出现梯度消失的问题,为了解决反向传播的梯度问题,LSTM方法被提出。
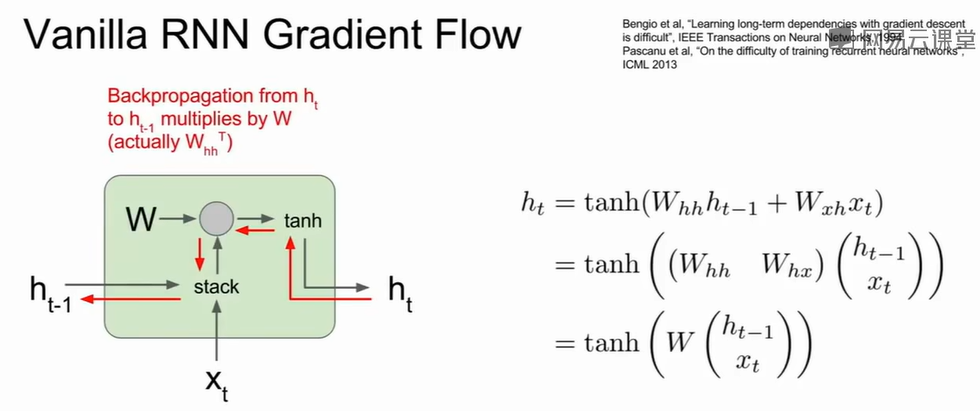
LSTM把每个时步的细胞拆成四个门:f遗忘门,i输入门,g状态门,o输出门。
接收三个输入:上一个时间步的隐藏状态$h_{t-1}\\$,上一个时间步的细胞状态$C_{t-1}\\$,当前时间步的输入$x_t\\$。产生两个输出:当前时间步的隐藏状态ht,当前时间步的细胞状态$C_t\\$。其内部通过精巧的“门”结构来调控信息的流动,一个门是一个由Sigmoid函数和点乘运算组成的结构。
遗忘门决定要从上一个细胞状态 $C_{t-1}\\$中遗忘哪些信息,输入$h_{t-1}\\$和 $x_t\\$并将二者拼接后,通过一个Sigmoid函数,产生一个在[0, 1]之间的向量
$f_t\\$,$f_t\\$ 会与 $C_{t-1}\\$ 进行点乘。如果 $C_{t-1}\\$ 中的某个位置对应的 $f_t\\$
是0,那么该信息就会被遗忘;如果是1,则该信息会被完整保留。
输入门决定要在当前细胞状态中添加哪些新信息,$i_t\\$为[0,1]向量,$g_t\\$的取值被限制在[-1,1]。
$i_t = σ(W_i · [h_{t-1}, x_t] + b_i)\\$
$g_t = tanh(W_g · [h_{t-1}, x_t] + b_g)\\$
现在,我们将遗忘门和输入门的结果结合起来,更新细胞状态:$C_t = f_t*C_{t-1} +
i_t*g_t\\$。这个公式是LSTM的灵魂所在,$f_t*C_{t-1}\\$决定丢弃多少旧信息,$i_t*g_t\\$:决定添加多少新信息,整个操作是线性的(只有加法和乘法),这一点对于反向传播至关重要。
输出门基于更新后的细胞状态,决定下一个隐藏状态ht应该是什么。隐藏状态通常作为当前时间步的输出,并传递给下一个单元。
$o_t = σ(W_o · [h_{t-1}, x_t] + b_o)\\$
$h_t = o_t * tanh(C_t)\\$
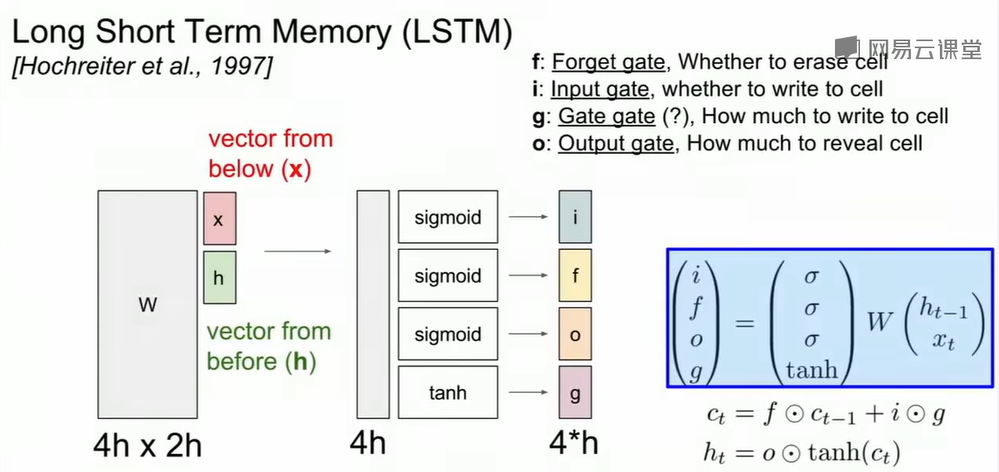
LSTM是如何优化反向传播的呢?虽然它仍然保留了权重矩阵,但没有直接参与梯度更新的运算。核心在于细胞状态
$C_{t}\\$的更新路径。
$C_t=f_t * C_{t-1} + i_t *g_t\\$
在反向传播时,梯度需要从$C_t\\$流回$C_{t-1}\\$。根据链式法则,$C_t\\$对 $C_{t-1}\\$的偏导数是$f_t\\$(遗忘门的输出)。而$f_t\\$是一个由Sigmoid产生的,值在[0, 1]之间但不是恒为0或1的向量,从而避免了矩阵乘法的问题。
VIT
VIT即Visual Transformer,是Transformer在视觉领域的应用。
Detection
除了分类出小猫,我们也想知道:猫在哪里?能不能框出来?
首先我们阐释一下localization(定位)和detection(识别)的区别。localization是我知道这张图片是猫,要找到猫在哪里;而detection需要在给定的图片中识别出是否存在猫(有可能存在多个物体),如果有猫找到在哪里。可以说,localization是detection的简化。
我们先说说定位任务。把这个问题视为regression,数据集标注好图像的标签以及框的坐标$(x,y,w,h)\\$,$(x,
y)\\$是边界框中心点相对于当前网格单元左上角的偏移量,值域[0,1];$(w,
h)\\$是边界框的宽度和高度相对于整个图片的比例,值域[0,1]。图像经过CNN处理后,定义两个损失函数:分类的损失和位置的损失,本质上是multi-task loss,对两个损失函数进行加权求和,超参数的设置往往需要实验。类似方式的还有姿态估计,对每个关节点的位置$(x,y)\\$进行标注,损失由每个部位的L2 Loss相加。
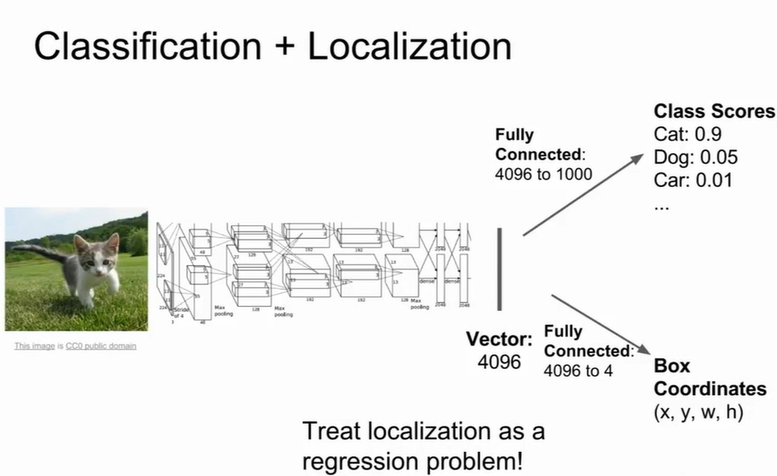
识别任务相较定位任务更加复杂,因为它不知道图像里是否确切有某个物体,接下来介绍几个方法。
Sliding Window
把图像切成块,用滑动窗口在不同图像块平移,将每个窗口识别为某个目标或背景,从而识别出目标。这种方法计算成本昂贵,因为每滑动一次就要用一次CNN。

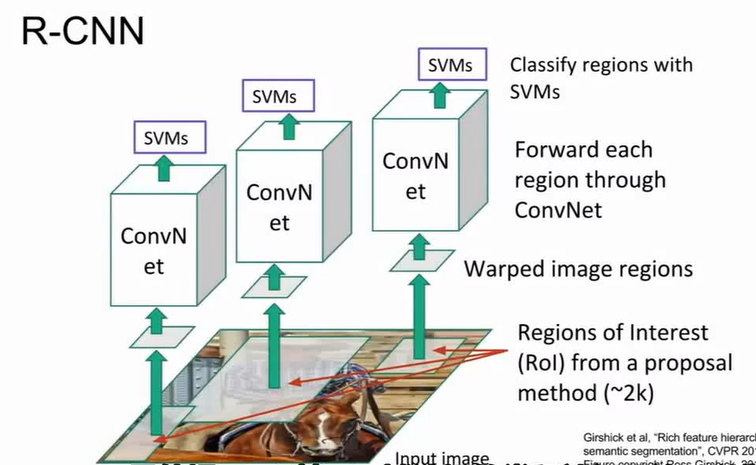
R-CNN
先提出Region Proposals的概念,我们通过区域选择网络选取图像中可能出现物体的区域,相对Sliding Window减少了无效背景的干扰,但是仍然会有很多噪声。
R-CNN提出了Regions of Interest(RoI)方法,先寻找可能含目标的图像块对感兴趣的区域进行处理,调整为固定尺寸
CNN处理后用SVM对区域进行分类。但是有很多问题,比如,选择模型没法根据具体情况进行训练,而且每次输入框尺寸不一样,CNN要反复跑,训练速度不佳。
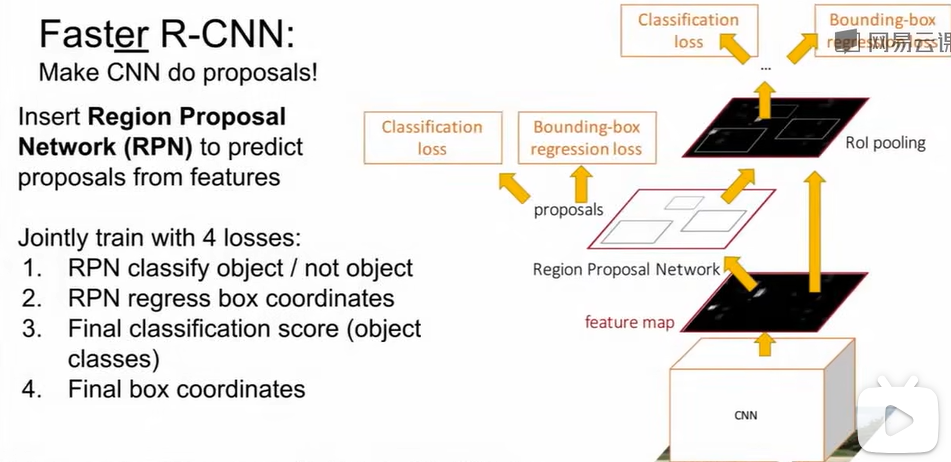
Faster R-CNN
在R-CNN基础上改进得到了Faster R-CNN。先只跑一次卷积得到feature map并选取感兴趣区域,经过
RoI Pooling将尺寸固定后通过共享的全连接层进行分类与边界的训练。
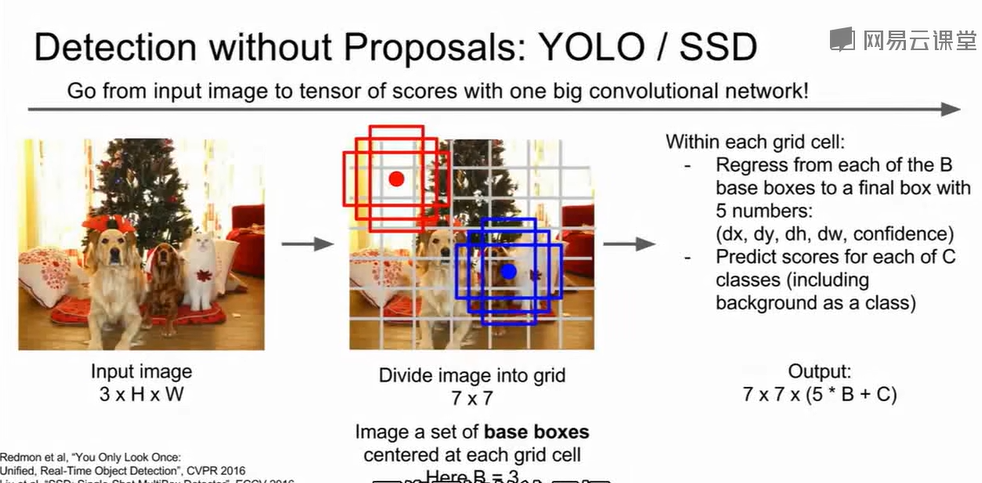
YOLO
但最知名的YOLO算法并没有采用选择感兴趣区域的方法,这里我们简要讲解一下YOLOv1的原理。其核心是把图像切成网格(如7*7),并且预测某类目标出现在框中的概率有多大,输出$7 * 7* (5 * B +
C)\\$。而框的选取是围绕每一个网格的中心点取B个一定大小的box,每个box有五个参数。$(x, y, w,
h)\\$描述边界框的位置和大小,confidence(置信度)表示这个框内包含一个目标的可能性有多大,以及这个框的位置预测得准不准。$C\\$代表数据集中所有待检测的类别总数,输出包括每个类别的评分。对于每个网格单元,它只预测一组类别概率,记作
$P(Class_i |
Object)\\$,即“如果这个网格里有物体,那么这个物体属于第i个类的概率是多少”。训练时,损失包括有目标的框坐标回归误差;置信度误差加权(有目标
vs 无目标);类别预测误差。
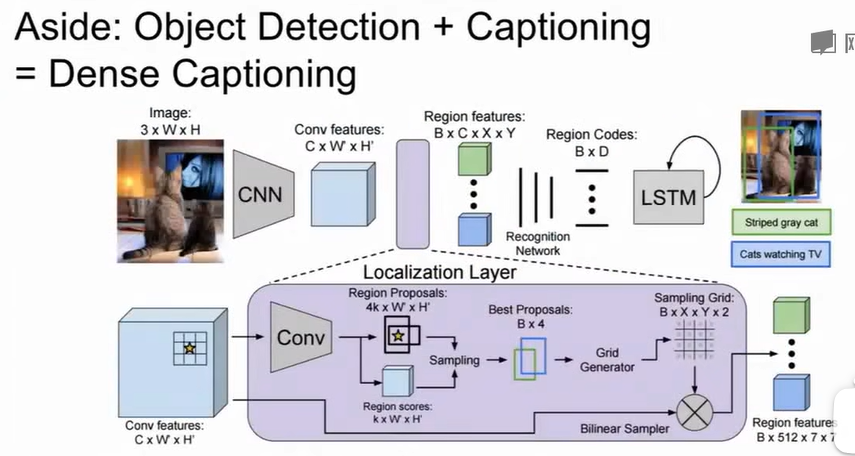
除此之外,我们还可以延伸到识别加标注的任务Dense Captioning,框出区域并且附以文字说明,接下来的操作和识别任务类似,只不过最后用RNN对候选框进行预测文字说明,这也是多模态模型的早期形态。
Segmentation
分割任务是识别任务的延伸,在识别出物体的基础上分割出轮廓。
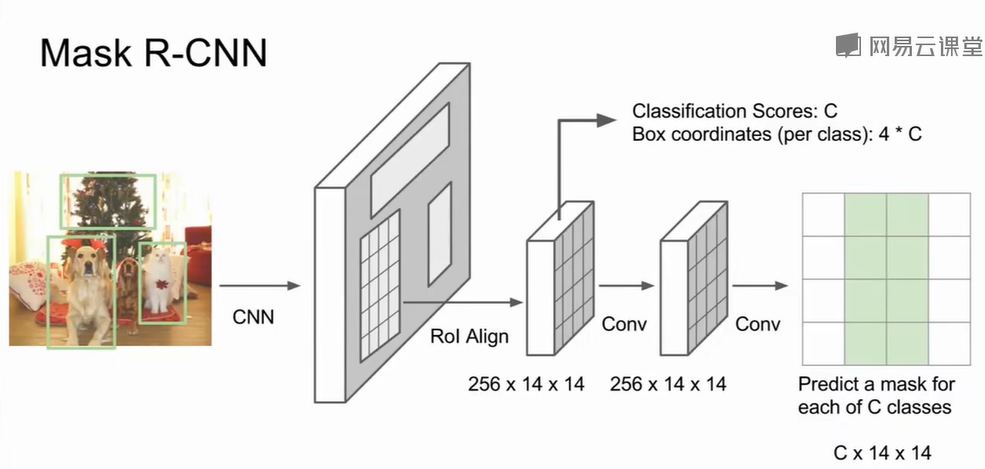
Mask R-CNN
其核心可概括为Faster R-CNN +
一个并行的掩码预测分支。它为每个检测到的物体预测一个二值的掩码,精确勾勒出物体的像素级轮廓。损失函数加上像素级的轮廓掩码预测:$L_{\text{mask}} = -\frac{1}{m^2} \sum_{i,j} \left[
y_{ij} \log M_{ij}^k + (1 - y_{ij}) \log (1 - M_{ij}^k)
\right]\\$
这个思路在姿态估计上同样有效,需要添加一个关节点坐标分支。
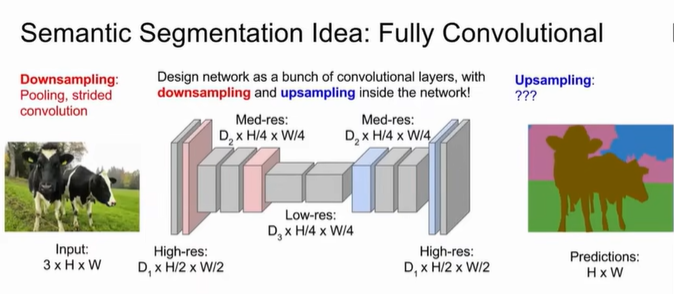
Semantic Segmentation
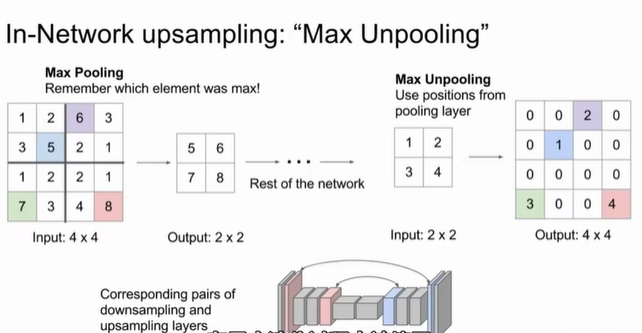
每个像素都有标签标注,但存在问题:两个牛重叠在一起,像素标签相同,无法区分。改进方法是滑动窗口sliding window,用图像块代替像素,但是计算成本高。fully convolutional的改进是采用downsampling和upsampling结合的网络。由于maxpooling有去噪效果,但分割需要明显的区分,我们采用unpooling对像素进行重复与填充增加边界处的噪声,也就是upsampling的过程。
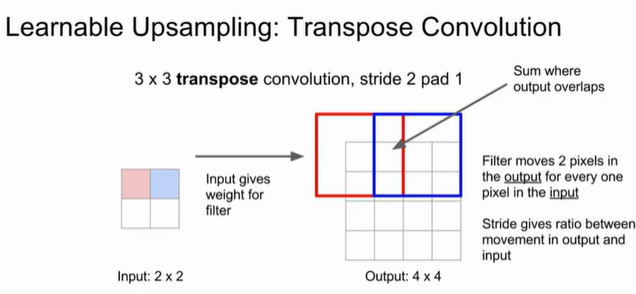
我们可以引申到transpose convolution的概念,类似于卷积的逆运算,其本质便是upsampling。我们用0对每个元素行列之间进行填充使之变成稀疏矩阵,随后进行步长为1的普通卷积,最终得到的特征图就是输入像素的特征印记在该位置叠加的结果。那为什么叫转置(transpose)卷积呢?为了实现尺寸上的逆向,它使用普通卷积矩阵
$C\\$的转置 $C^T\\$,乘以被展平的输入向量 $x\\$,得到一个更大的输出向量 $o'\\$。即$o' = C^T
x\\$。
U-Net
Visualizing
机器学习的一大问题就是黑箱,而可视化能让我们提升视觉任务的可解释性,也能在实验中更了解每一步的情况。除此之外,通过对中间特征的捕捉我们可以完成一些风格转换任务。
First Layer
卷积神经网络的第一层往往是卷积层,观察每个卷积核的输出我们可以初步观察图像的特征。

Filters/Kernels
低层卷积核可以直接可视化,因为它们学到的是图像的基本特征(如边缘、颜色、纹理);高层卷积核虽然也能画出来,但往往看不出明显的可解释模式。

Last Layer
最后一层往往输出得分,但对一些复杂的输出我们需要dimensionality reduction。如,常见的PCA主成分分析。t-SNE也是一种降维方法。
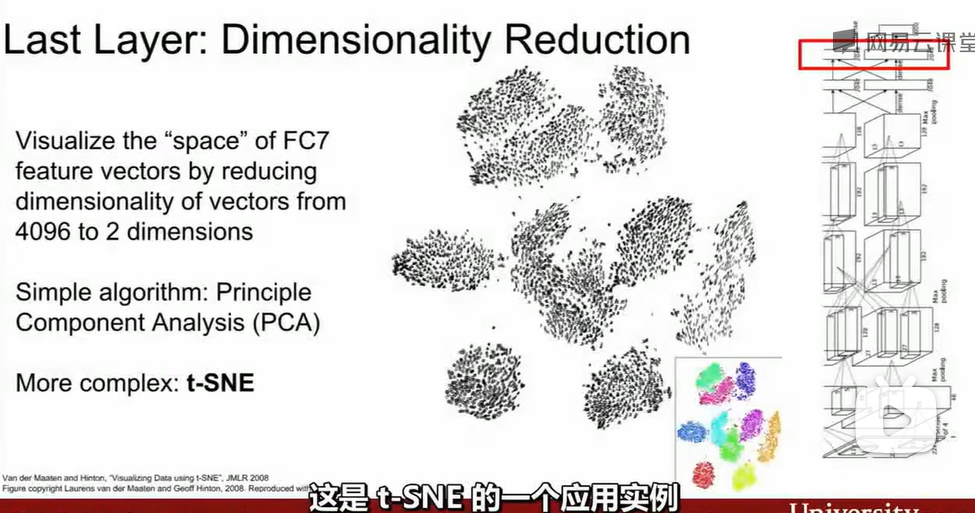
Activations
feature map可以看到这层网络关注到了什么特征。
maximally activating patches可以看到最强烈激活某个卷积核的图像片段。


Occlusion Experiments
通过遮挡图像并绘制CNN热力图,可以确认某块图像的重要性。
$S(x, y) = p_{orig} - p_{occluded}(x, y)\\$
其中:$p_{\text{orig}}\\$表示原图预测的类别概率;$p_{\text{occluded}(x, y)}\\$表示遮挡 $(x, y)\\$ 区域后的类别概率;$S(x, y)\\$表示该区域对模型预测的重要性(值越大说明越关键)。

Saliency Maps
对像素进行扰动计算对分类分值的影响。往往会和grabcut混合使用,但缺乏监督。
$\text{Saliency}(x, y) = \left| \frac{\partial y_c}{\partial x_{ij}} \right|\\$

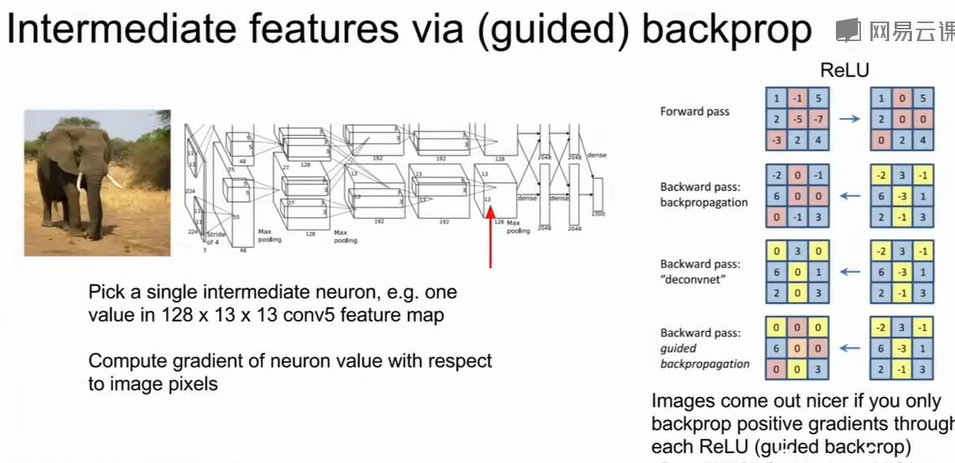
Intermediate Features Via (Guided) Backprop
引导式反向传播,在标准反向传播中,梯度传播方式为$\delta_l = \delta_{l+1} \cdot
f'(z_l)\\$,其中 $f'(z_l)\\$
是ReLU的导数。若前向时 $z_l <
0\\$(ReLU输出为0),梯度被阻断;若上层梯度
$\delta_{l+1}\\$
为负,仍可能产生负向信号。
Guided Backprop进行了改进,只保留正向贡献: $$
\delta_l =
\begin{cases}
\delta_{l+1}, & \text{if } \delta_{l+1} > 0 \text{ and } z_l >
0 \\
0, & \text{otherwise}
\end{cases}\\
$$
也就是:不让负梯度传播回来且不让前向激活为负的神经元贡献梯度。
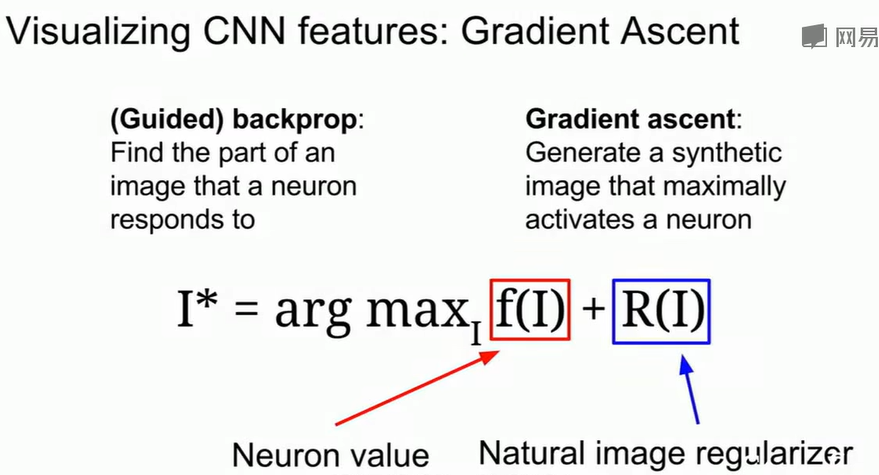
CNN features
Gradient Ascent用于优化图像特征的可视化,$f(I)\\$表示神经元对输入图像 $I\\$ 的激活值,$R(I)\\$是正则项,保证图像自然、不发散,可表示为$I^* = argmax_{I} [f(I) + R(I)]\\$。
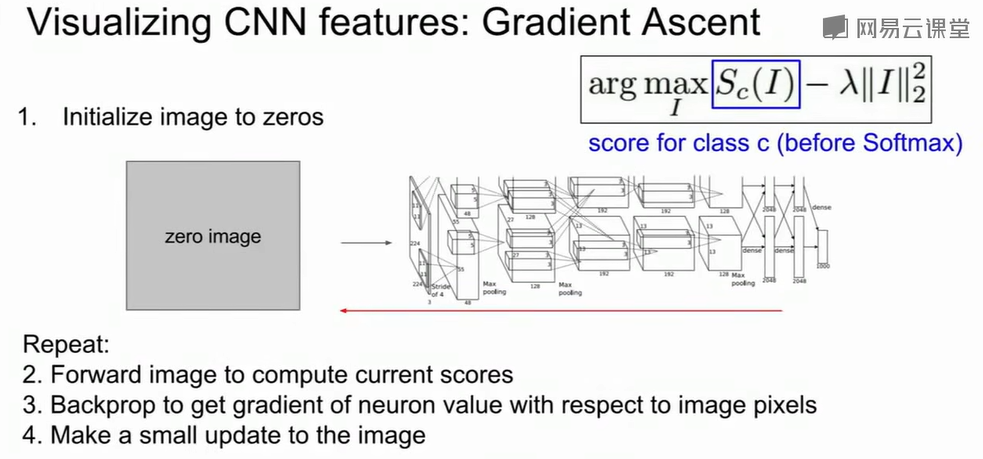
另一种表达是$I^* = argmax[S_c(I) -
\lambda||I||_2^{2}]\\$ ,$S_c(I)\\$表示类别 c 的得分,$|I|_2^2\\$表示图像像素的L2范数正则项,$\lambda\\$表示正则项权重。也就是找到一张图
$I^*\\$,能最大程度地激活类别$c\\$的神经元,同时又保持图像看起来合理。
但是一般的正则化可能引入过多噪声,我们选用更平滑的方案Gaussian Blur/clip pixels with small values to 0/clip pixels with small gradients to 0。

Fooling images/Adversial Examples
用错误的标签混淆,对比视觉任务中的差异,类似于
GAN的想法。

Deep Dreaming:Amplify Existing Features
通过网络放大检测到的特征,可以应用到风格迁移。

Feature Inversion
通过最小化以下目标函数,从特征向量中“反解”出一张图像:
$$ \|\Phi(x) - \Phi_0\|^2 + \lambda R(x)\\ $$
其中,$\Phi(x)\\$为当前图像在CNN某层的特征;$\Phi_0\\$为目标特征向量(来自原图像);$R(x)\\$:正则化项,保持图像平滑自然;$\lambda\\$:权重系数,用于平衡特征匹配与图像自然度。通过优化该式,可以重建出在特征空间上与原图匹配的图像,从而揭示CNN不同层捕捉到的特征信息及其损失情况。


Texture Synthesis
通过Nearest Neighbour进行邻近像素的合成。

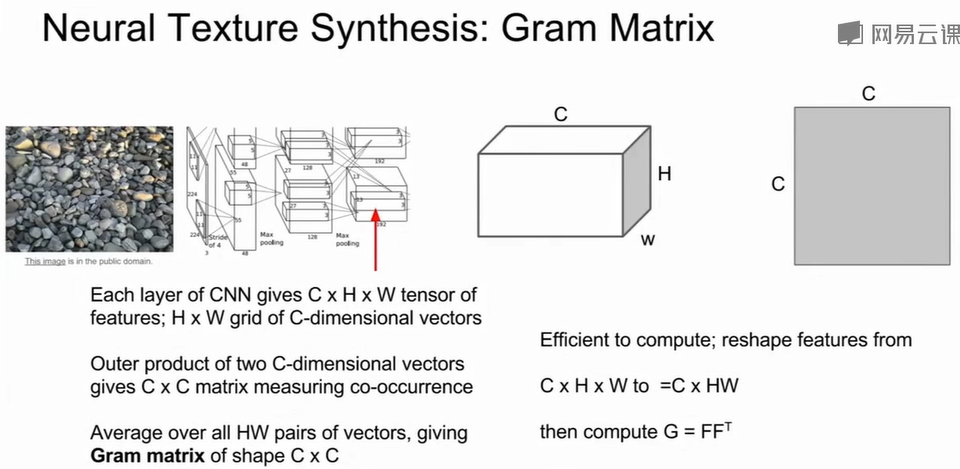
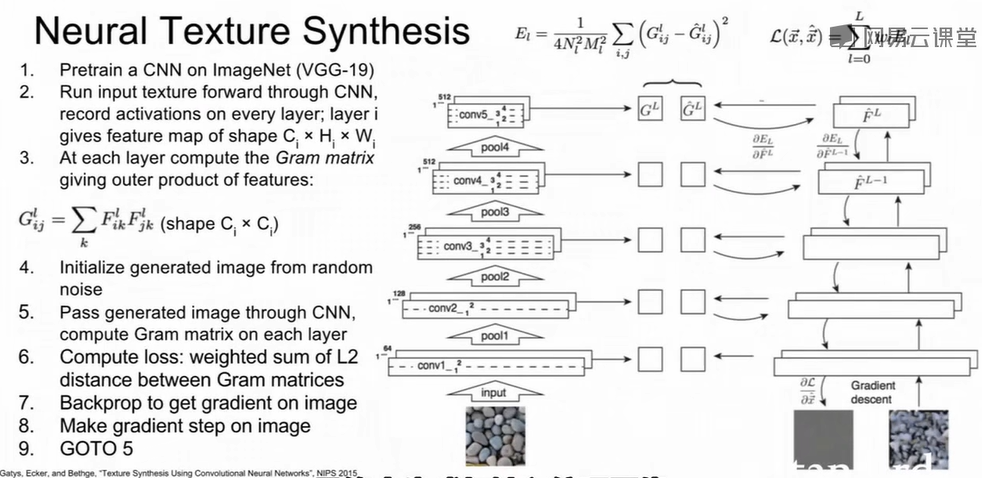
Neural Texture Synthesis
神经纹理合成通过Gram Matrix实现。先输入纹理图像,通过预训练CNN得到每层特征图$F^l \in \mathbb{R}^{C_l \times H_l \times
W_l}\\$,随后计算Gram矩阵(特征通道间的共现统计)$G^l = F^l (F^l)^T\\$,其中 $G^l\\$ 尺寸为 $C_l
\times C_l\\$,表示不同特征的相关性。
然后,随机初始化图像 $x\\$,并让其Gram矩阵与目标图匹配:$x^* = \arg\min_x \sum_l w_l \|G^l(x) -
G^l(I_{\text{style}})\|^2\\$
最后通过反向传播更新 $x\\$,逐步优化生成结果。
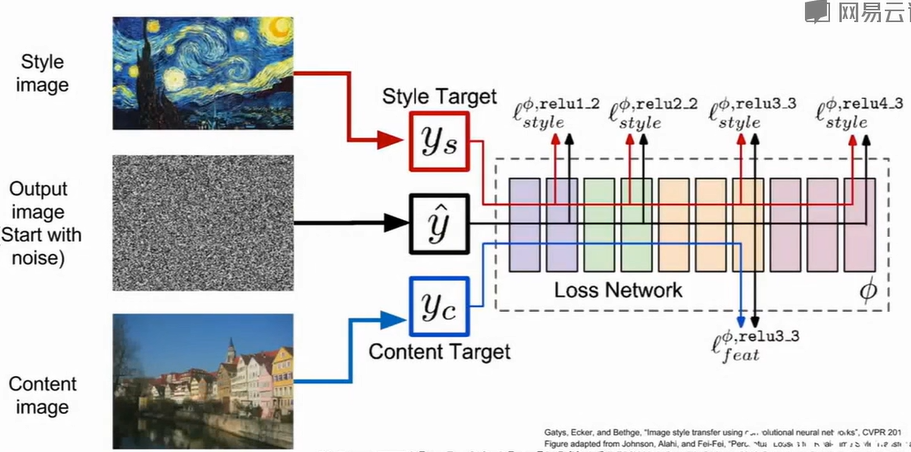
Nueral Style Transfer
输入有content image + style image +
output image(从noise开始优化),随后我们通过CNN特征提取并用Gram进行风格转换,损失函数包括内容损失和风格损失,损失函数权重的改变会导致内容和风格的倾向。
$$
\mathcal{L}_{\text{content}} = \frac{1}{2}\|\Phi^l(\hat{y}) -
\Phi^l(y_c)\|^2 \\ \mathcal{L}_{\text{style}} = \sum_l w_l
\|G^l(\hat{y}) - G^l(y_s)\|^2\\
$$

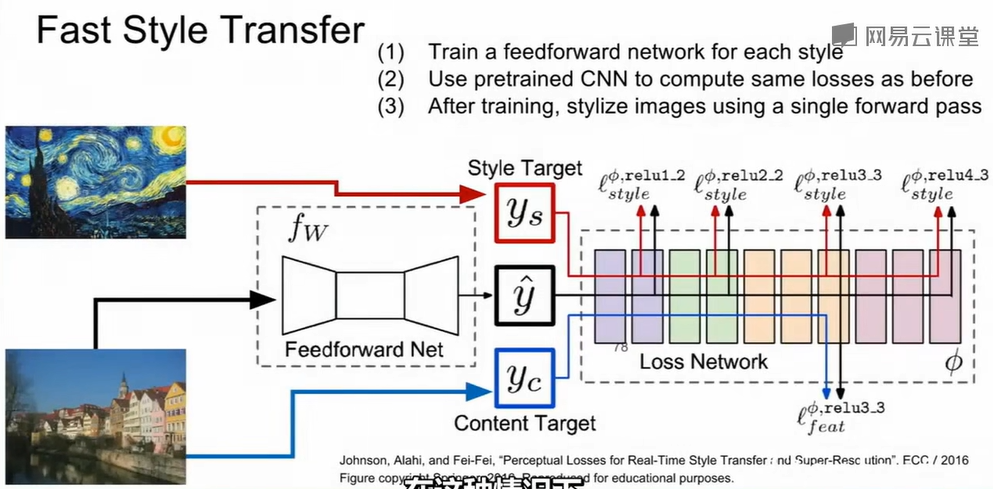
但原始方法每生成一张图都要从随机噪声开始反复迭代优化,计算量极大、无法实时使用。Fast Style Transfer
的关键改进是:训练一个前馈网络(Feedforward Network)来“学会”这种优化过程。训练阶段用预训练CNN计算内容损失与风格损失,监督前馈网络学习生成风格化图像,推理阶段只需一次前向传播即可完成风格迁移,速度快到可以实时应用。
通过Conditional Instance Normalization (CIN),让一个网络能够处理多种艺术风格,而无需为每种风格单独训练模型。在标准实例归一化中$x_{\text{norm}} = \frac{x - \mu}{\sigma}, \quad z =
\gamma x_{\text{norm}} +
\beta\\$,在CIN中每种风格都有独立的参数 $(\gamma_s,
\beta_s)\\$;卷积层共享,但根据风格标签选择不同的缩放与偏移;训练时随机切换风格,学习多风格映射。
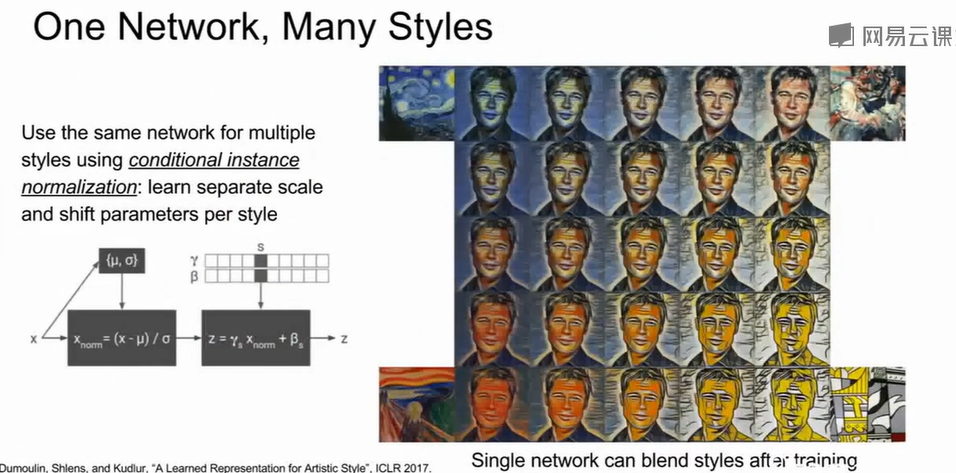
Generative Models
生成任务需要从给定的训练数据中学习到生成新样本的方法,是无监督学习任务。生成方法我们可以归为explicit density estimation(显式密度估计)和implicit density estimation(隐式密度估计)两类。下面的Pixel RNNS and CNNS/VAE属于显式,GAN属于隐式。

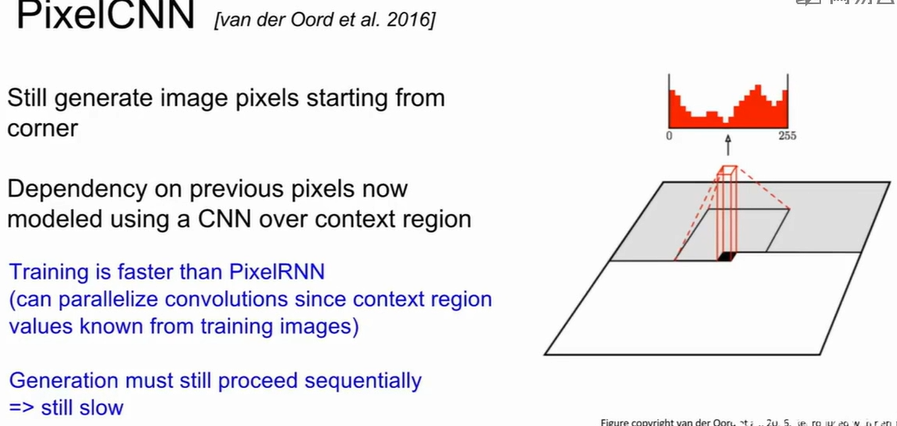
Pixel RNNs and CNNs
图像生成被拆分为像素序列,每个像素的分布由前面像素条件决定。 $p_{\theta}(x) = \prod_{i=1}^{n}p_{\theta}(x_i|x_1,...,x_{i-1})\\$
目标是最大化训练集似然$\max_\theta \sum_x \sum_i \log p_{\theta}(x_i|x_1,...,x_{i-1})\\$,等价于最小化交叉熵损失,即比较模型输出的像素分布与真实像素,让真实像素获得更高概率,从而学习到整个图像分布。往往使用链式法则通过一维分布求解最大化似然,并用神经网络表述概率分布。
RNN建模像素间依赖,在先前像素的基础上对拐角的像素进行预测,但是逐序列生成太慢了。

CNN同样自回归建模,但用masked convolution代替RNN。卷积核仅访问已生成像素(上方、左方),避免信息泄漏。CNN比RNN快,因为训练阶段可并行(整图卷积)。
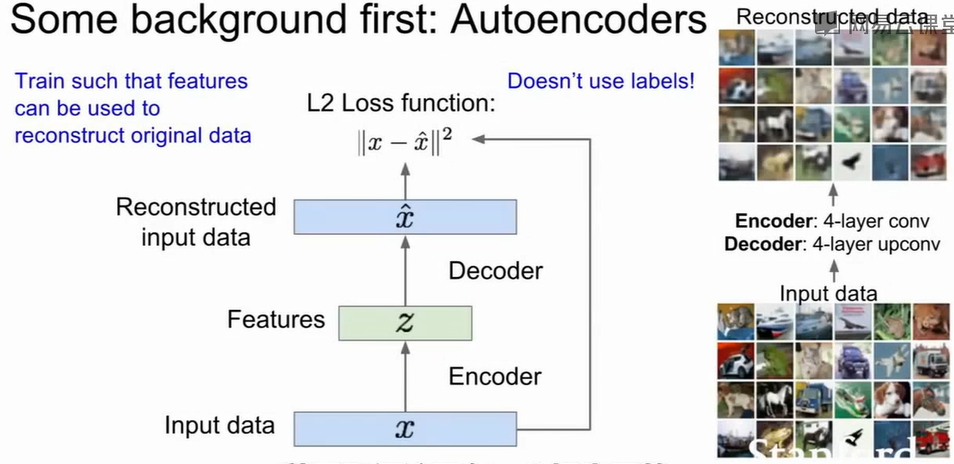
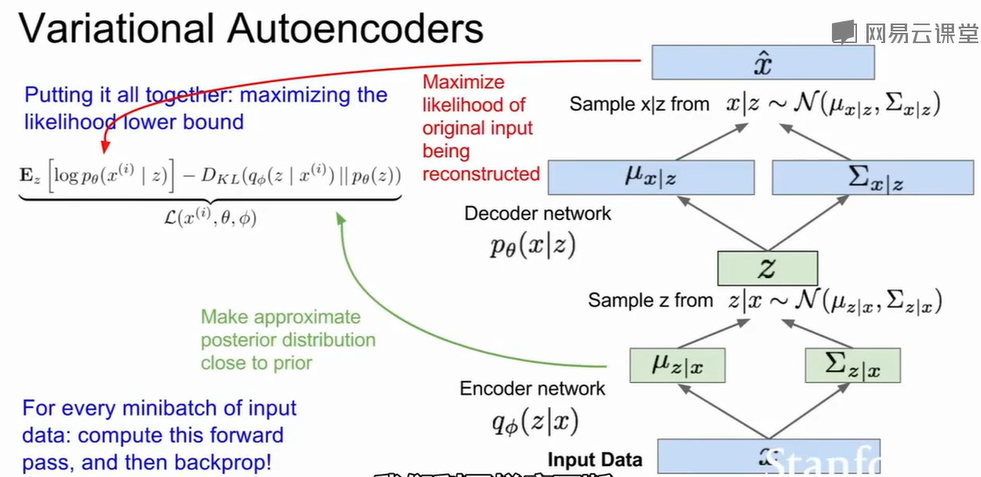
VAE(Variational Autoencoders)
我们先说说Autoencoder。自编码器由两部分组成:Encoder(编码器)将输入数据x压缩为低维特征表示$z =
f_{\text{enc}}(x)\\$;Decoder(解码器)从特征z重建出原始输入$\hat{x} =
f_{\text{dec}}(z)\\$。通过最小化重建误差,使输出尽量接近输入:$\mathcal{L} = \|x - \hat{x}\|_2^2\\$。
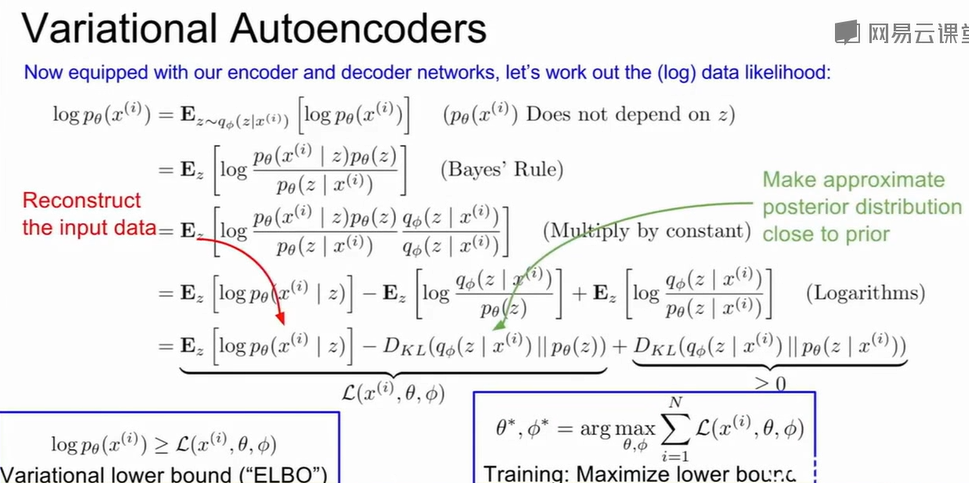
变分自编码器在自编码器的基础上,引入概率分布建模和变分推断,目标是学习一个潜在空间分布,使得从该空间采样也能生成与训练数据相似的样本,从而实现真正的生成模型。
生成过程中,$z \sim p_\theta(z), \quad x \sim p_\theta(x|z)\\$,其中$p_\theta(z)\\$为潜在变量的先验分布(通常为标准正态分布),$p_\theta(x|z)\\$为解码器生成图像的条件分布,整个观测样本x的概率为$p_{\theta}(x) = \int p_{\theta}(z)p_{\theta}(x|z)dz\\$。
Encoder输出潜变量的均值与方差$q_\phi(z|x) = \mathcal{N}(\mu_{z|x},
\Sigma_{z|x})\\$,Decoder根据采样的z生成重建图像$p_\theta(x|z)\\$。由于真实后验$p_\theta(z|x)\\$无法直接求解,引入近似分布$q_\phi(z|x)\\$来替代它,这一步称为变分推断。

通过推导得到似然下界: $$
\log p_\theta(x) \ge
\mathbb{E}_{z \sim q_\phi(z|x)}[\log p_\theta(x|z)] -
D_{KL}(q_\phi(z|x)\,||\,p_\theta(z))\\
$$
其中,重建项最大化输入数据的重建似然,使生成结果接近原图;KL散度项约束编码器输出分布接近标准正态先验,使潜在空间连续且可采样。
由于积分形式的边缘似然$p_\theta(x)=\int p_\theta(z)p_\theta(x|z)dz\\$无法直接优化,因此通过从x编码到潜变量z,再从z解码回x时引入高斯分布以增加随机性,用均值和协方差对潜在空间进行建模:$z = \mu_{z|x} + \Sigma_{z|x}^{1/2} \cdot \epsilon, \quad \epsilon \sim \mathcal{N}(0,I)\\$
这样可将随机性从网络参数中分离,使得整个过程能够反向传播。最终的优化目标为:$\mathcal{L}(x;\theta,\phi) = \mathbb{E}*{z \sim q*\phi(z|x)}[\log p_\theta(x|z)] - D_{KL}(q_\phi(z|x),||,p_\theta(z))\\$
训练时通过三步完成:首先前向传播完成“编码 → 采样 →
解码”,然后计算重建误差与KL散度,最后反向传播以联合优化编码器与解码器参数$(\theta, \phi)\\$。
GAN(Generation Adversial Network)
生成对抗网络的本质依然是输入任意噪声经过网络输出图像。网络分为Generator Network和Discriminator Network。生成网络生成fake images,和real images对比训练Discriminator。

目标函数是minmax函数博弈。
$\min_{\theta_g} \max_{\theta_d} \Big[\mathbb{E}_{x \sim p_\text{data}(x)}[\log D_{\theta_d}(x)] - \mathbb{E}_{z \sim p(z)}[\log (1 - D_{\theta_d}(G_{\theta_g}(z)))]\big]\\ $
其中,$D_{\theta_d}(x)\\$为判别器对真实样本 x
输出为真的概率(0–1),$D_{\theta_d}(G_{\theta_g}(z))\\$为判别器对生成样本
$G(z)\\$输出为真的概率
。判别器希望最大化该目标函数,使真伪样本区分得更好(对真实图像 $x\\$:输出 $D(x)
\approx 1\\$;对生成图像 $G(z)\\$:输出 $D(G(z)) \approx
0\\$)。判别器的训练相当于一个二分类问题,真实样本标记为1,生成样本标记为0。生成器希望最小化该目标函数,使得生成样本尽可能逼真。目标是让判别器认为生成图像也是真实的,即$D(G(z)) \approx 1\\$,生成器不断优化,使
$G(z)\\$ 更接近真实数据分布 $p_\text{data}(x)\\$。
训练过程构成一个零和博弈:判别器最大化损失 ⇒ 学会区分真假,生成器最小化损失 ⇒ 欺骗判别器,当二者达到平衡时$p_G(x) = p_\text{data}(x), \quad D(x) = 0.5\\$,判别器无法再区分真假样本。


当判别器训练得很强时,$D(G(z)) \approx 0\\$,此时生成器的梯度 $\nabla_{\theta_g}\log(1 - D(G(z)))\\$ 极小,导致生成器几乎无法更新,训练停滞。为增强梯度信号,提出改用以下目标,即不再最小化 $\log(1 - D(G(z)))\\$,而是最大化$\log D(G(z))\\$,这样即使生成样本较差,梯度仍保持较大,生成器能持续学习。
$$
\max_{\theta_g} \mathbb{E}_{z \sim p(z)}[\log
D_{\theta_d}(G_{\theta_g}(z))]\\
$$ 

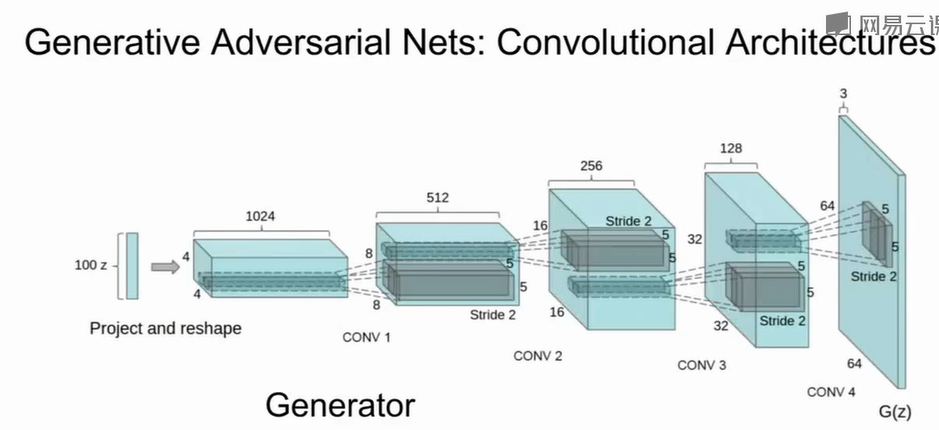
CNN能更好地建模局部相关性与空间层次信息,相比全连接层,通过Convolutional Architectures能够帮助Generator生成更好的样本。
GAN有很多有意思的应用,比如interpretable vector math,通过向量的加减叠加实现视觉效果的合成。除此之外,GAN还被广泛用于风格转换等任务,从而衍生出了GAN家族。

Diffusion
VLM
CLIP
附录1 Training Details
无论是什么视觉任务,训练神经网络必然是绕不开的,我们来回顾一下训练的细节。
Experiment
实验是一个babysitting的过程,需要密切的关注全流程中各指标的变化情况。
最直观的就是通过cross-validation评估训练结果以及训练过程中loss的变化曲线(波动或者平缓),进而调整lr(decay),batch_size,regularization等参数,达到最优效果。在选取新参数时,往往会采用random search/grid search的方法。不过,目前的pytorch已经集成好了这些功能。
Fancier optimization
SGD
会出现“之”字形更新,核心原因在于其梯度的随机性。它使用单个或小批量样本的梯度来估计真实梯度,该估计带有噪声和高方差。当损失函数的等高线呈狭长山谷状时,这种带有噪声的更新方向会与指向全局最小值的理想路径产生剧烈偏差。为了解决这个问题,我们引入Momentum,在某个方向上赋予动量,使其不会停留在局部最小值点或鞍点,也抵消了噪声影响。
AdaGrad通过累计梯度调整自适应学习率,在凸函数上效果较好;而RMSProp引入
decay_rate解决梯度减小过快的问题,二者结合得出了Adam。
first_moment = 0
second_moment = 0
while True:
dx = compute_gradient(x)
first_moment = beta1 * first_moment + (1 - beta1) * dx # Momentum
second_moment = beta2 * second_moment + (1 - beta2) * dx * dx # RMSProp
first_unbias = first_moment / (1 - beta1 ** t) # bias correction
second_unbias = second_moment / (1 - beta2 ** t) # bias correction
x -= learning_rate * first_moment / (np.sqrt(second_moment) + 1e-7) # RMSProp如果loss以平滑的曲线下降,那么证明是合适的学习率。
Loss
我们回顾一下各大损失函数的特点。但一般来说,ReLU是最常用的。
sigmoid:值域[0,1],但是存在梯度消失($x\\$过大时斜率趋近于0),e增加计算资源,激活函数输出不是以0为中心(恒为正,不同参数梯度方向全部相同)等问题。(有时预处理会用零均值化:$\hat{x_i}=x_i-\mu\\$,改变数据分布近似以0为中心)tanh:值域[-1,1],优化了sigmoid的输出问题,但是梯度消失无法解决。(Leaky) ReLU:$max(0,x)\\$,虽然解决了梯度消失问题,但是$x<0\\$时神经元会死亡。引入Leaky ReLU,在负数区域引入小斜率α,表达式为$max(\alpha x,x)\\$ELU:x < 0时$\alpha(e^x-1)\\$,引入非线性关系,更鲁棒。maxout:$max(w_1^Tx+b_1,w_2^Tx+b_2)\\$,但参数量翻倍,增加了计算资源。
Weight Initialize
初始参数设置过小,神经元容易崩溃;初始参数设置过大,神经元容易饱和。为了解决这个问题,提出了Xavier初始化,其在标准高斯分布里采样,并补偿了输入连接数fan_in带来的方差放大效应。
w = np.random.randn(fan_in,fan_out)/np.sqrt(fan_in)BatchNorm $$
\frac{x-E(X)}{\sqrt{var x}}\\
$$
即Z-Score标准化的公式,一般在卷积层后进行归一化,统一输入值的分布。
对于 (N, C, H, W)
的卷积网络特征图,本质上是在一个批次的所有样本的同一个通道上做归一化,计算的是
N*H*W
个元素的均值和方差,在CV领域应用较多。而LayerNorm本质上是对单个样本的所有特征做归一化,计算的是
C*H*W
个元素的均值和方差,在NLP领域应用较多。
Regularization
正则化方法有很多,主要包括以下几种:集成学习(训练多个模型预测取平均值防止过拟合提升性能);Dropout,随机选取失活神经元(激活函数值设为0)
随机性;batch normalization,噪声 $y=f_W(x,z)\\$,$y=f(x)=E_z[f(x,z)]=\int
p(z)f(x,z)dz\\$;data augmentation,随机转换(翻转/剪切/放缩/旋转/…);drop connect,随机丢弃网络连接;fractional max pooling,使用随机大小的池化区域;stochastic depth,在训练时随机跳过某些层。
Transfer learning
例如在ImageNet上预训练,然后修改输出维度/网络层数,帮助自己的样本进行训练。
附录2 Classification Code
# train.py
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
# 定义训练设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义数据变换和增强
train_transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((32, 32)), # 调整图像大小
torchvision.transforms.RandomCrop(32, padding=4), # 随机裁剪
torchvision.transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转
torchvision.transforms.RandomRotation(degrees=15), # 随机旋转
torchvision.transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 颜色抖动
torchvision.transforms.RandomGrayscale(p=0.1), # 随机灰度化
torchvision.transforms.ToTensor(), # 转换为张量
torchvision.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) # CIFAR10标准化
])
test_transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((32, 32)), # 调整图像大小
torchvision.transforms.ToTensor(), # 转换为张量
torchvision.transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)) # CIFAR10标准化
])
# 准备数据集
train_data = torchvision.datasets.CIFAR10('../dataset', train=True, transform=train_transform,download=True)
test_data = torchvision.datasets.CIFAR10('../dataset', train=False, transform=test_transform,download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print(train_data_size)
print(test_data_size)
# 打包数据
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
class CIF(nn.Module):
def __init__(self):
super(CIF, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
cif = CIF()
cif.to(device)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 优化器
learning_rate = 1e-2 # 1x(10)^(-2)
optimizer = torch.optim.SGD(cif.parameters(), lr=learning_rate)
# 记录训练次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter('../logs')
# 计算开始时间
start_time = time.time()
for i in range(epoch):
print('-----------第{}轮训练开始------------'.format(i + 1))
cif.train() # 和cif.eval()只对部分网络有用(dropout等)
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = cif(imgs)
loss = loss_fn(output, targets)
# 优化器调优
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0: # 每100次打印一次
end_time = time.time()
print('训练时长:{}'.format(end_time - start_time))
print('训练次数:{}, loss: {}'.format(total_train_step, loss.item()))
writer.add_scalar('train_loss', loss.item(), total_train_step)
# 测试步骤开始
cif.eval()
total_test_loss = 0 # 损失指标
total_accuracy = 0 # 准确率指标
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
outputs = cif(imgs)
loss = loss_fn(outputs, targets)
accuracy = (outputs.argmax(1) == targets).sum() # 1为横着方向,返回每一行最大的索引,True则返回1
total_test_loss = total_test_loss + loss.item()
total_accuracy = total_accuracy + accuracy
print('整体测试集上的loss:{}'.format(total_test_loss))
print('整体测试集上的正确率:{}'.format(total_accuracy / test_data_size))
writer.add_scalar('test_loss', total_test_loss, total_test_step)
writer.add_scalar('test_accuracy', total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
# 保存模型
torch.save(cif, 'cif_{}.pth'.format(i))
print('模型已保存')
writer.close()
# tensorboard --logdir=logs --port=6007# test.py
import torch
import torchvision
from PIL import Image
from torch import nn
from torch.utils.tensorboard import SummaryWriter
img_path = '../dataset/train/dog/dog.jpg'
img = Image.open(img_path)
image = img.convert('RGB')
transforms = torchvision.transforms.Compose(
[torchvision.transforms.Resize((32, 32)), torchvision.transforms.ToTensor()])
image = transforms(image)
# print(image.shape)
class CIF(nn.Module):
def __init__(self):
super(CIF, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
writer = SummaryWriter('../logs')
model = torch.load('../code/cif_9.pth',map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
writer.add_graph(CIF(), image)
writer.add_image('CIF', image, dataformats='NCHW')
writer.close()


